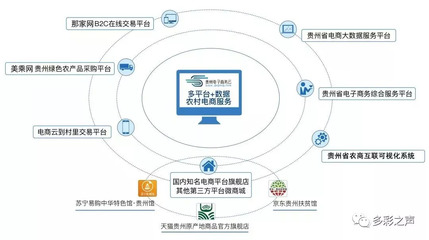
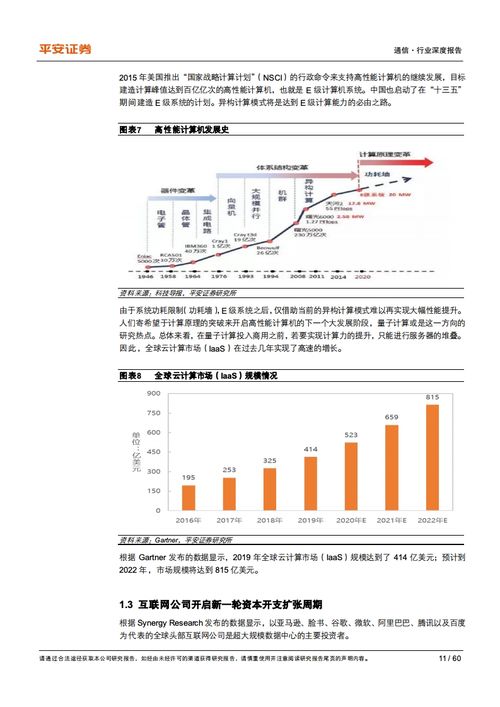
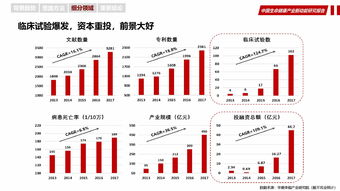
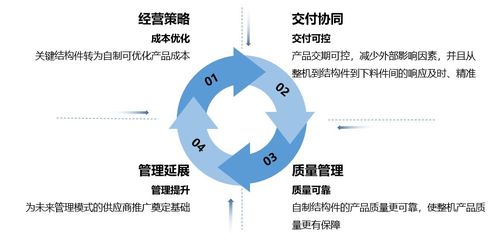
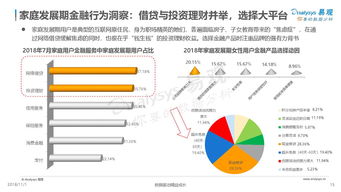
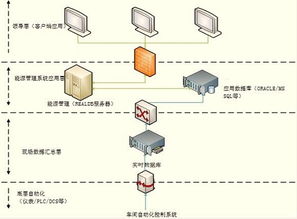
互聯網金融公司分布式數據庫運維實踐 挑戰、策略與未來

引言:數字化時代的核心引擎
在互聯網金融的浪潮中,數據是業務的血液,而數據庫則是承載這顆心臟的核心引擎。隨著用戶規模激增、交易并發量呈指數級增長,傳統集中式數據庫在性能、擴展性和可用性上已捉襟見肘。分布式數據庫憑借其彈性伸縮、高可用和容災能力,已成為行業技術架構升級的必然選擇。從集中式到分布式的轉型,不僅是技術的更迭,更是一場深刻的運維理念與實踐的重塑。
第一部分:核心挑戰與痛點分析
- 數據一致性與高性能的平衡:金融業務對數據的強一致性要求極高,而分布式環境下的跨節點事務、全局一致性(如分布式事務ACID保障)與低延遲、高吞吐的性能目標往往存在天然矛盾。
- 彈性伸縮與成本控制:業務流量存在明顯的波峰波谷(如促銷、秒殺活動),需要數據庫能夠快速、平滑地擴縮容。如何實現自動化資源調度,同時避免資源浪費,是運維成本控制的關鍵。
- 高可用與容災的復雜性:分布式架構將單點故障風險分散,但也引入了網絡分區、腦裂等新風險。構建跨地域、多活容災體系,確保RTO(恢復時間目標)與RPO(恢復點目標)滿足金融級要求(如RPO≈0),復雜度呈幾何級數上升。
- 運維監控與故障定位的難度:系統從單體變為分布式網狀結構,監控指標爆炸式增長。一次性能抖動或故障,其根因可能隱藏在多個服務、數據庫節點與網絡鏈路中,定位與排查如同“大海撈針”。
- 安全與合規的剛性約束:金融數據安全、隱私保護(如《個人信息保護法》)、審計溯源等合規要求,必須在分布式架構的每一個環節(數據分片、傳輸、存儲)中得到嚴格落實。
第二部分:核心運維策略與實踐
- 架構選型與設計先行
- 選型原則:根據業務特征(如OLTP或OLAP傾向、數據模型)選擇合適的技術路線(如NewSQL、基于中間件的分庫分表)。明確一致性模型(強一致、最終一致)的適用場景。
- 數據分片策略:采用合理的分片鍵(如用戶ID、業務主體ID),避免數據傾斜與熱點。設計上預留擴容空間,支持在線數據重分布。
- 自動化運維平臺建設
- 資源生命周期管理:通過平臺實現實例的自動部署、配置管理、版本升級、擴縮容(如基于預測算法的彈性伸縮),將人工操作降至最低。
- 智能化監控與告警:構建統一的監控大盤,覆蓋從硬件、網絡、數據庫實例到慢查詢、事務狀態的全鏈路指標。引入AIOps,實現異常檢測、根因分析與智能降噪,變“救火”為“預防”。
- 高可用與容災體系構建
- 同城多活與異地災備:在同城數據中心內部署多副本,利用Raft/Paxos等共識協議保證高可用。建設異地異步/半同步容災集群,定期進行災備演練,確保切換流程可靠、數據完整。
- 混沌工程實踐:主動注入故障(如節點宕機、網絡延遲、磁盤IO異常),驗證系統韌性,持續優化應急預案與恢復流程。
- 性能優化與容量管理
- SQL審核與慢查詢治理:建立上線前SQL審核規范,利用執行計劃分析、索引優化等手段從源頭杜絕性能隱患。對線上慢查詢進行實時追蹤與優化。
- 容量規劃與成本優化:建立精細化的容量模型,基于歷史數據與業務預測進行容量規劃。利用存儲分層、數據冷熱分離、閑置資源回收等技術優化存儲與計算成本。
- 安全與合規內嵌
- 全鏈路數據加密:實現數據傳輸(TLS/SSL)與靜態數據加密,嚴格密鑰管理。
- 細粒度訪問控制與審計:實施基于角色的最小權限訪問原則,所有數據庫操作留有完整、不可篡改的審計日志,滿足合規審計要求。
第三部分:未來展望與
分布式數據庫的運維正朝著平臺化、自動化、智能化、安全原生的方向演進。隨著云原生、Serverless、人工智能等技術的深度融合,未來的運維將更加聚焦于業務價值交付與SLA保障,而非底層基礎設施的瑣碎管理。
而言,互聯網金融公司的分布式數據庫運維實踐,是一場以穩定性、效率、成本、安全為四大支柱的持續旅程。它要求技術團隊不僅精通數據庫技術本身,更要具備全局的架構視野、工程化的平臺思維和應對復雜性的系統方法論。唯有將穩健的運維實踐深深嵌入到技術體系的骨髓中,方能支撐起互聯網金融業務在數字化浪潮中的高速、穩健航行。
如若轉載,請注明出處:http://www.sunrec.com.cn/product/61.html
更新時間:2026-01-06 13:38:56